一个用于数据中心管理和运营的人工智能(AI)策略,你需要的不仅仅是数据和一些非常聪明的人。如果还要满足业务的需求,选择特定的案例并理解那些会影响AI结果的数据类型—然后验证这些结果—将是人工智能能否满足您的业务需求的关键。
通过关注特定的案例,可以扩展早期的成功,并逐步获取进一步的价值。管理人员不需要是人工智能专家,但Uptime InsTItute建议数据中心管理人员对正在发展应用的人工智能建立基本的深度和广度。这样做意味着他们如何可以更好地确定需要多少数据,以及如何透过人工智能来使用这些数据,这在验证产出的结果和建议时是至关重要的。
在UpTIme InsTItute Intelligence最近撰写的一份题为《非常智能的数据中心:人工智能将如何推动运营决策》(Very smart data centers: How artificial Intelligence will power operaTIons decisions)的报告中,提出应该对数据中心的人工智能有更好理解的观点。
作为第一步,让我们谈谈关于人工智能的几点。首先,演算法和模型有什么不同? 在推广人工智能的人可以拿这些术语来表示相同的东西,虽然它们可能不尽相同。
演算法是一系列数学步骤或计算指令。它是一个自动指令集。演算法可以是一条指令,也可以是一串指令—它的复杂度取决于每条指令的简单或复杂程度,以及/或演算法需要执行的指令数量。
在人工智能中,模型是指能够处理数据并提供对数据的预期响应或是数学模型的结果。例如将演算法应用于数据集,结果将会是模型。因此,模型是一个或多个算法的结果。如果输入到演算法中的数据发生变化,或者相同的数据通过不同的演算法输入,模型就会发生变化。
另一个非常重要的特性是目前数据中心使用的两种主要人工智能技术:机器学习和深度学习。
机器学习技术主要有三种类型:
监督学习:人类提供一个模型和训练数据。演算法获取训练数据并对模型进行微调,使输入和输出/响应更紧密地匹配。随着时间的推移以及数据的增加,演算法能进一步改进模型,并能够对新数据的响应做出合理的预测。监督机器学习在数据中心和其他行业中是最常被使用的一种方式。
无监督学习:演算法从未标记的数据中发现模式或内在架构。在某些场景中,无监督机器学习技术会被拿来与监督机器学习技术相结合。实际上,从无监督机器学习的输出数据可以成为监督机器学习的训练数据。
强化学习:人类提供一个模型和未标记的数据。当一套演算法确定数据所产生的最佳化结果时,它会得到一个正的数学“奖励”。(来自谷歌的开源强化学习框架被命名为多巴胺。) 通过提供反馈,它可以通过不同的变化来进行学习,而强化学习是最新的机器学习技术。
深度学习(Deep learning)是机器学习的一个子集,它使用多层人工神经网络来构建基于大量数据的演算法,这些演算法能够找到一种最优化的方式来独自做出决策或执行任务。人类提供训练数据和演算法,计算机将这些输入分解成一个非常简单的概念层次。每个概念成为中立网络上的一个数学节点。深度学习不使用来自人类的机器学习模型,而是像使用神经网络一样使用训练数据,它的工作原理像一个决策树。它根据自己对培训数据的分析建立了新的模型。
哪种技术最适合哪种用例?这取决于算法的质量和复杂度,以及所使用的模型和数据。但是,如果所有这些都是相同的,那么有一些特定的技术特别适合于特定的用例。
有些人说,深度学习可以发现更大程度的低效,因为它不受已知模型的约束。另一方面,监督机器学习能做到更加透明(使得领域专家更容易验证结果),而且自动化的速度也更快。
它可能有所不同,但是下面是一些非常适合不同类型的机器学习和深度学习的案例。
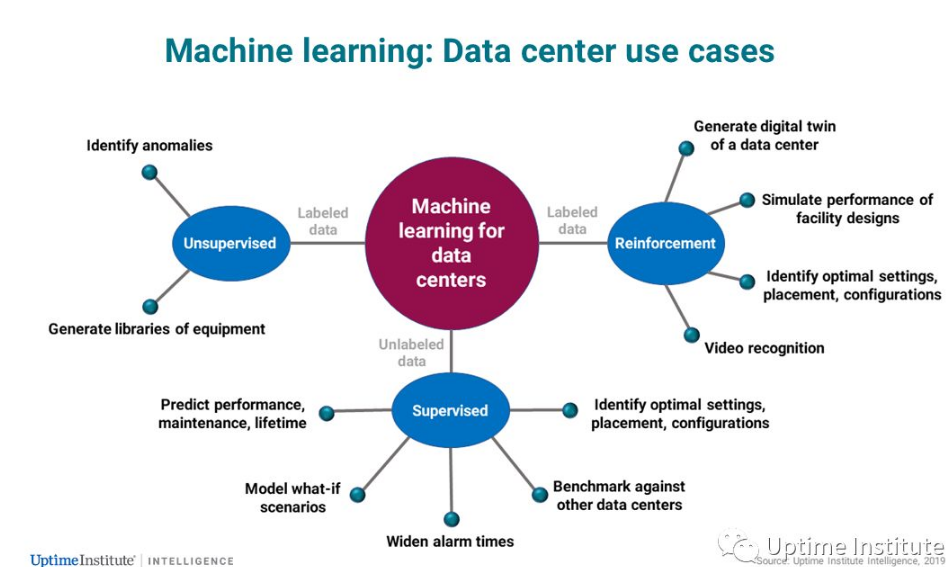
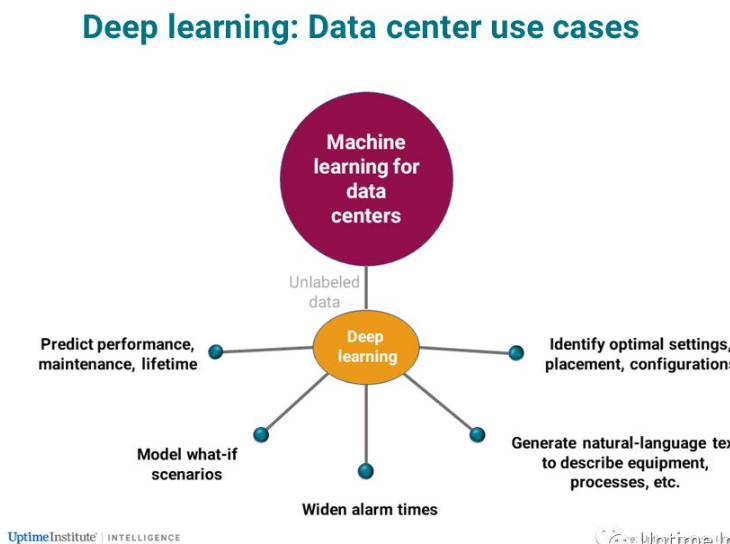
虽然现在还处于早期阶段,但是随着时间的推移,某些技术可能会在未来主导特定的需求。
操作人员至少应该了解正在应用的人工智能,并达到一定深度和广度的基本知识水平。如果采用人工智能来帮助运营,要求供应商显示模型中的数据点以及这些节点之间的关系—换句话说,需要了解人工智能是如何使用这些数据来提出相关的建议。最后,不论是否由人员来进行操作,跟踪结果总是很重要的。
来源:云数据中心
文章来源:精密空调 http://www.dataaire.com.cn



